
1、问题现象
其他部门的研发同学反馈调用我们服务的Dubbo接口异常,dubbo控制台中显示noProvider:
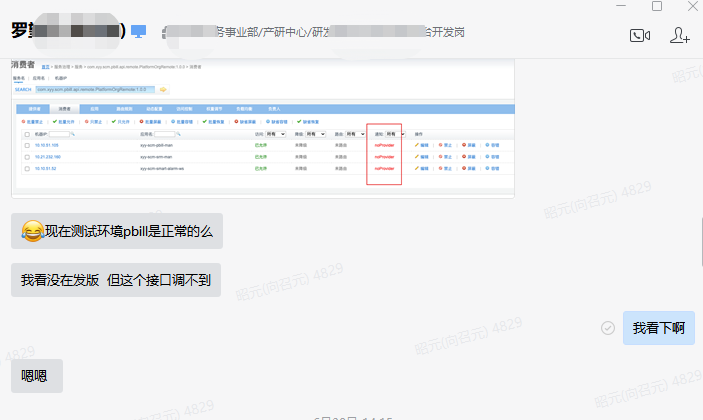
2、排查过程
对于这样的现象,初步推测是测试环境pbill服务挂掉了,于是登录测试机器执行jps -lvm | grep pbill,发现服务还在,但是执行top命令却发现进程CPU占用已经达到100%:
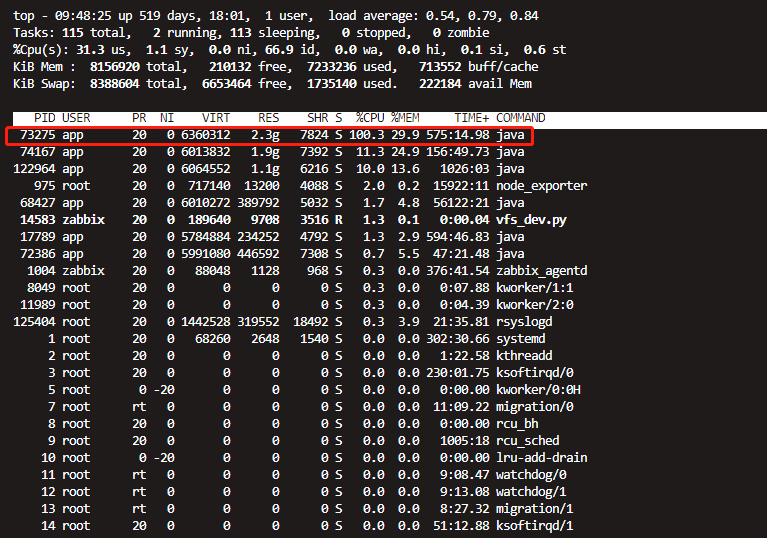
看现象推测代码里可能存在死循环或者外部调用量太大的情况,但是测试环境近期未部署代码,且原则上不会有高并发调用的情况,于是执行top -Hp 73275命令找出造成CPU 100%的具体线程:
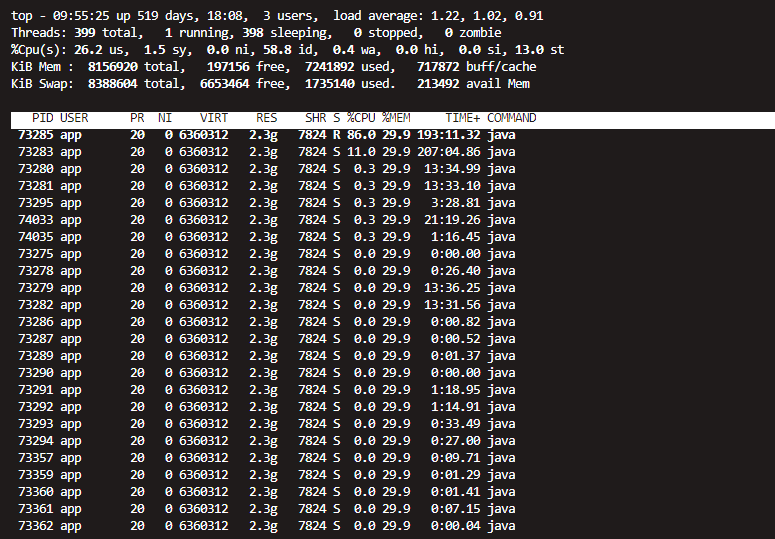
发现是PID为73285的线程占用CPU最多,将近90%,很有可能这个线程有问题。通过printf “%x\n” 73285转换成16进制如下:

然后执行jstack 73275 | grep "11e45"找到具体线程信息如下:

上网查询相关文档资料我们得知VM Thread是JVM自身启动的线程,会涉及到处理一些VM相关的操作,比如垃圾收集、线程堆栈转储、线程挂起和偏向锁撤销等,意味着如果系统发生频繁的GC会导致该线程非常繁忙,通过执行jstat -gcutil 73275 500 10每隔500毫秒打印一次GC信息:
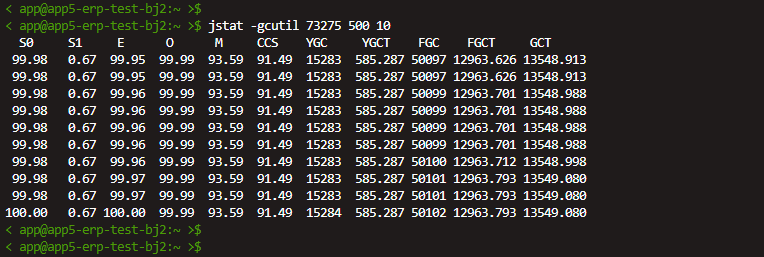
从执行结果可以得出如下信息:
- 系统Full GC很频繁,几乎能达到1次/秒,与推测符合;
- 堆内存年轻代和老年代已使用空间率几乎100%,这也是系统发生Full GC的直接原因。
到此为止,我们不难推测:系统可能发生内存泄漏,导致大量堆内存占用,几乎填满整个堆内存空间,造成JVM频繁进行垃圾收集,导致进程CPU飙升到100%,最终造成服务不可用。但是测试环境一般情况下使用较少,到底是什么对象能占据2G的堆内存空间呢?
于是通过JVM自带的工具jmap将堆内存dump出来:
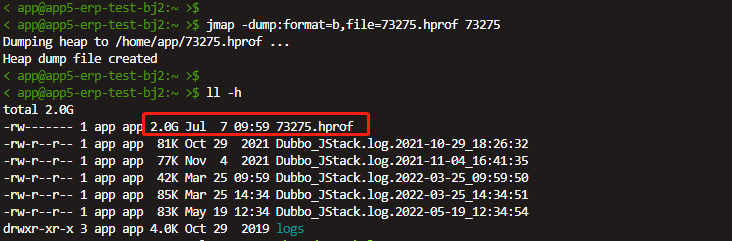
可以看出dump出的文件几乎和堆内存一样大,将hprof文件下载到本地,导入MAT工具进行近一步分析:
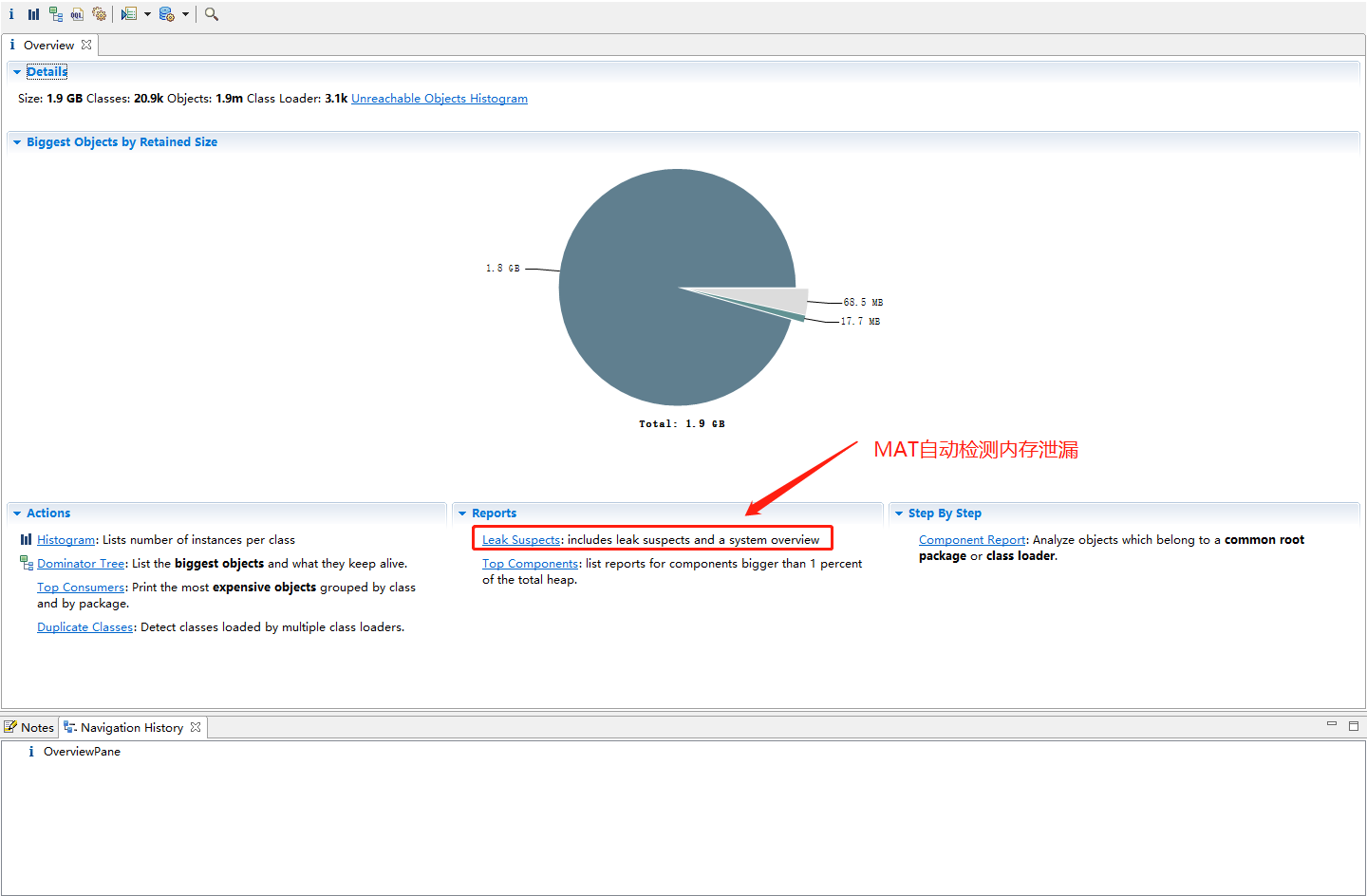
点击Reports下面的Leak Suspects让MAT自动帮我们检测内存泄漏:
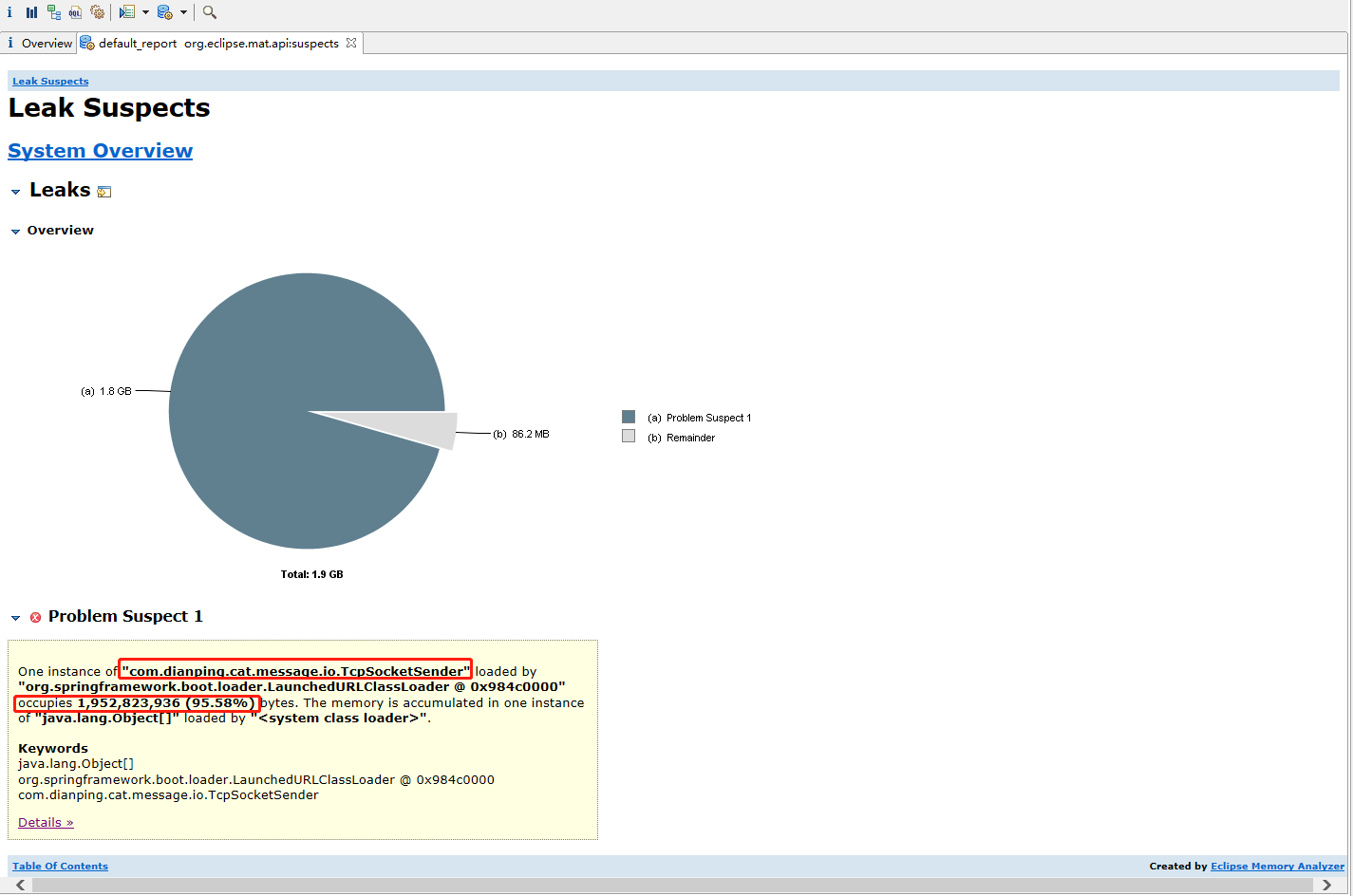
可以发现“com.dianping.cat.message.io.TcpSocketSender”对象占用了大约95.58%的堆内存,可以确定系统发生了内存泄漏,那具体是什么原因导致TcpSocketSender对象几乎占满了整个堆内存且不能被垃圾收集器回收呢?点击下面的Details近一步查看内存泄漏的详细信息:
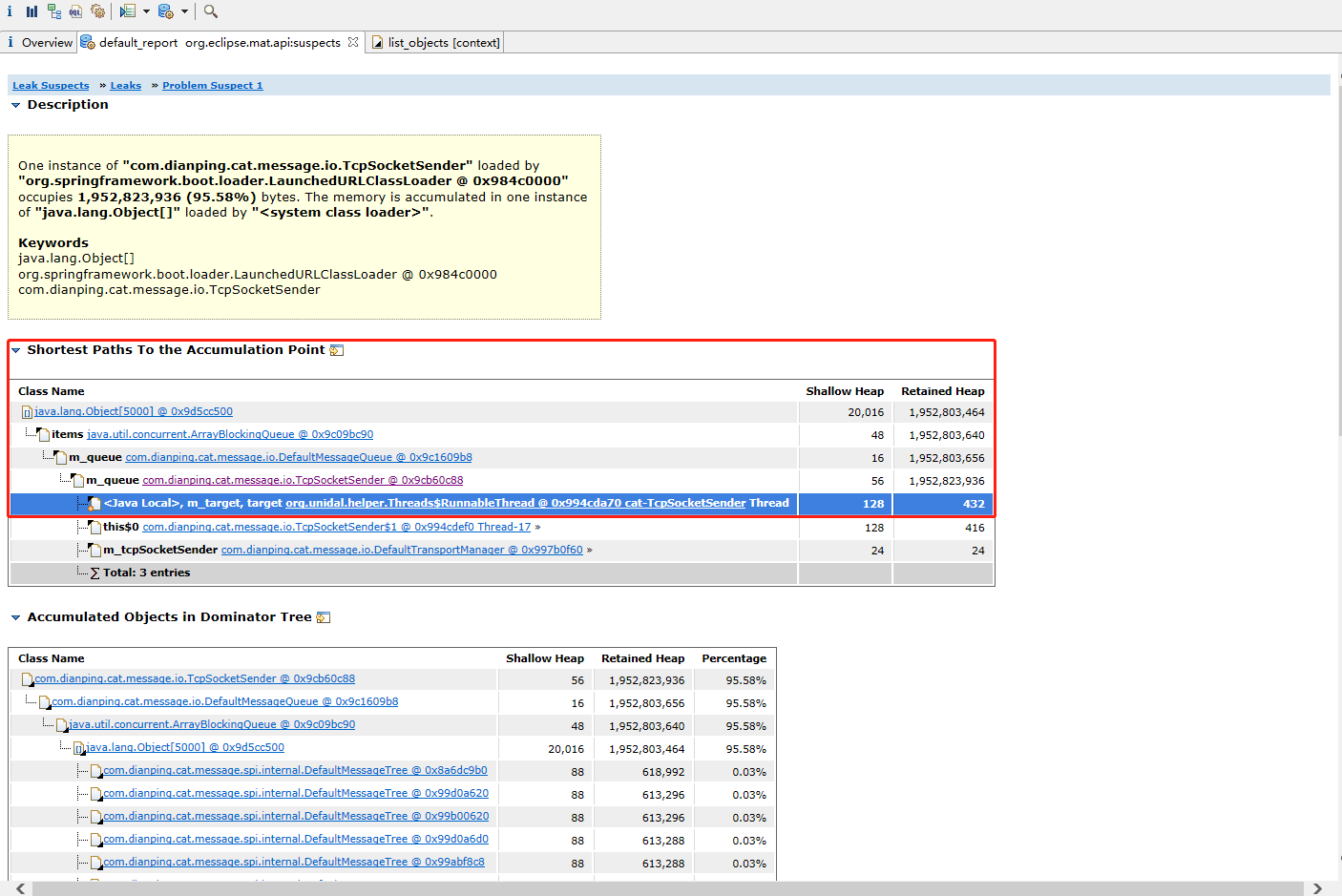
详情页中的Shortest Paths To the Accumulation Point表示GC Root到内存消耗聚集点的最短路径,如果某个内存消耗聚集点有路径到达GC Root,则该内存消耗聚集点不会被当做垃圾被回收。可以看出TcpSocketSender被GC Root对象“org.unidal.helper.Threads$RunnableThread”引用,导致无法回收,而“org.unidal.helper.Threads$RunnableThread”是Thread的子类:
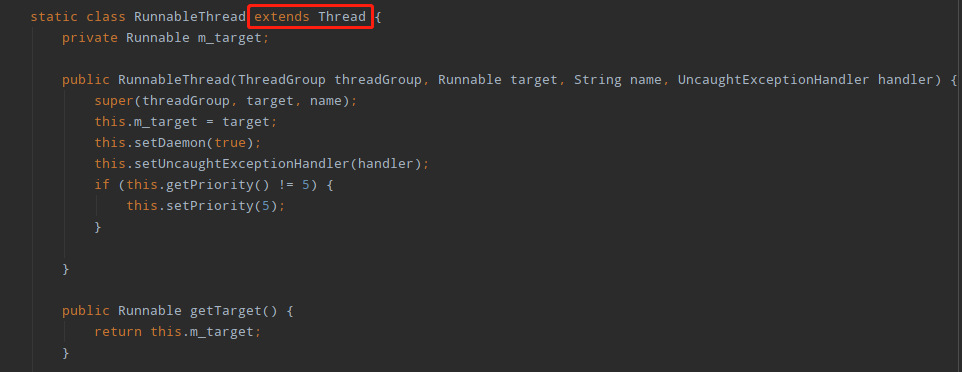
查看TcpSocketSender源代码可知TcpSocketSender类实现了Task接口,而Task接口继承了Runnable接口,所以TcpSocketSender类本质是一个Runnable的实现类,而“org.unidal.helper.Threads$RunnableThread”的m_target变量引用的即是TcpSocketSender类的对象,可以推测TcpSocketSender最终会被作为线程对象执行特定任务。
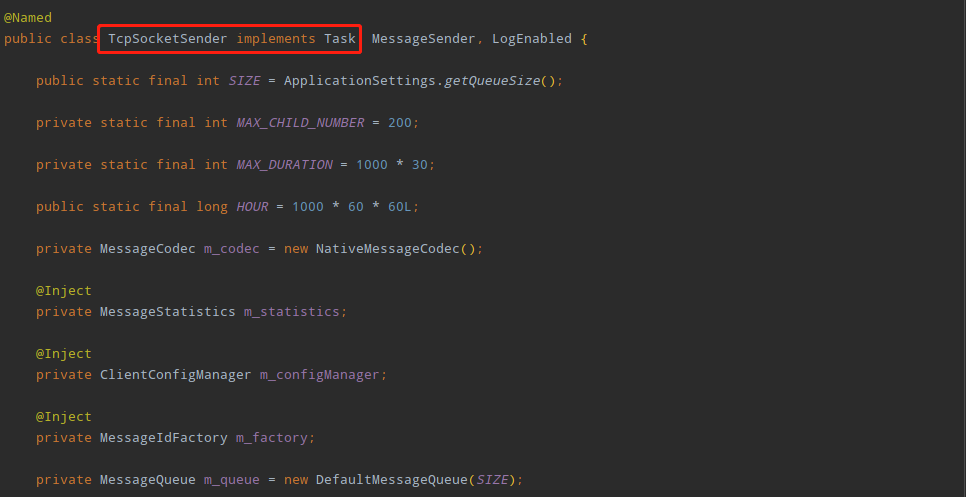

按照这个思路,找到TcpSocketSender类的run方法:
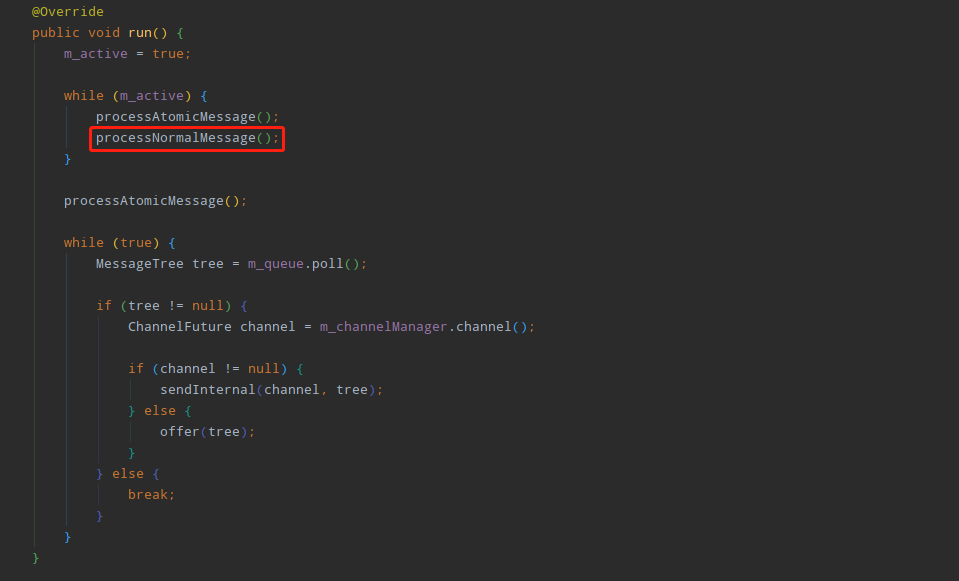
然后进入processNormalMessage方法:
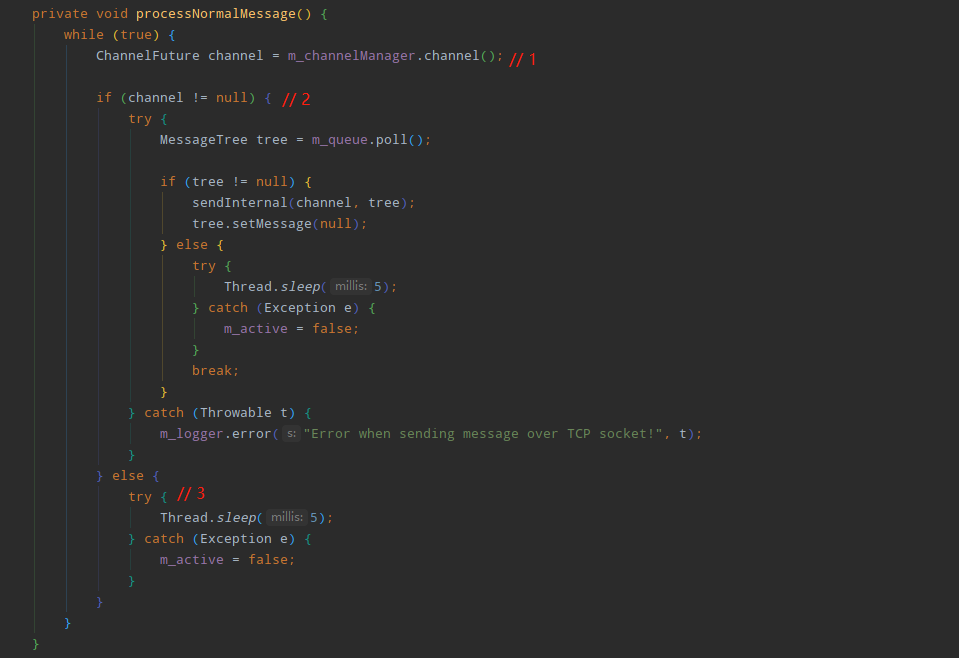
标注1处表示从ChannelManager中获取通过netty与CAT服务端建立连接后返回的ChannelFuture对象(过程比较复杂,不是本文重点分析对象,暂略过),正常情况下返回的ChannelFuture不会为空,程序会从m_queue中获取MessageTree对象通过Channel发送给CAT服务端,如果CAT客户端与服务端没有成功建立连接,则返回的ChannelFuture为空,在标注2处判断的时候会走else分支,也就是标注3的处理逻辑:线程不断休眠,while循环也不会break。然而CAT客户端仍然不停地采集监控数据放入m_queue中,随着时间的推移,由于CAT客户端与服务端未能成功建立连接,同时m_queue中的数据都发送不出去,保存的数据会越来越多,却又不能被GC收集器回收,最终导致内存溢出,为了验证此想法,再看看m_queue中具体保存的数据,在TcpSocketSender类上选择“List objects”,再选择“with outgoing references”:
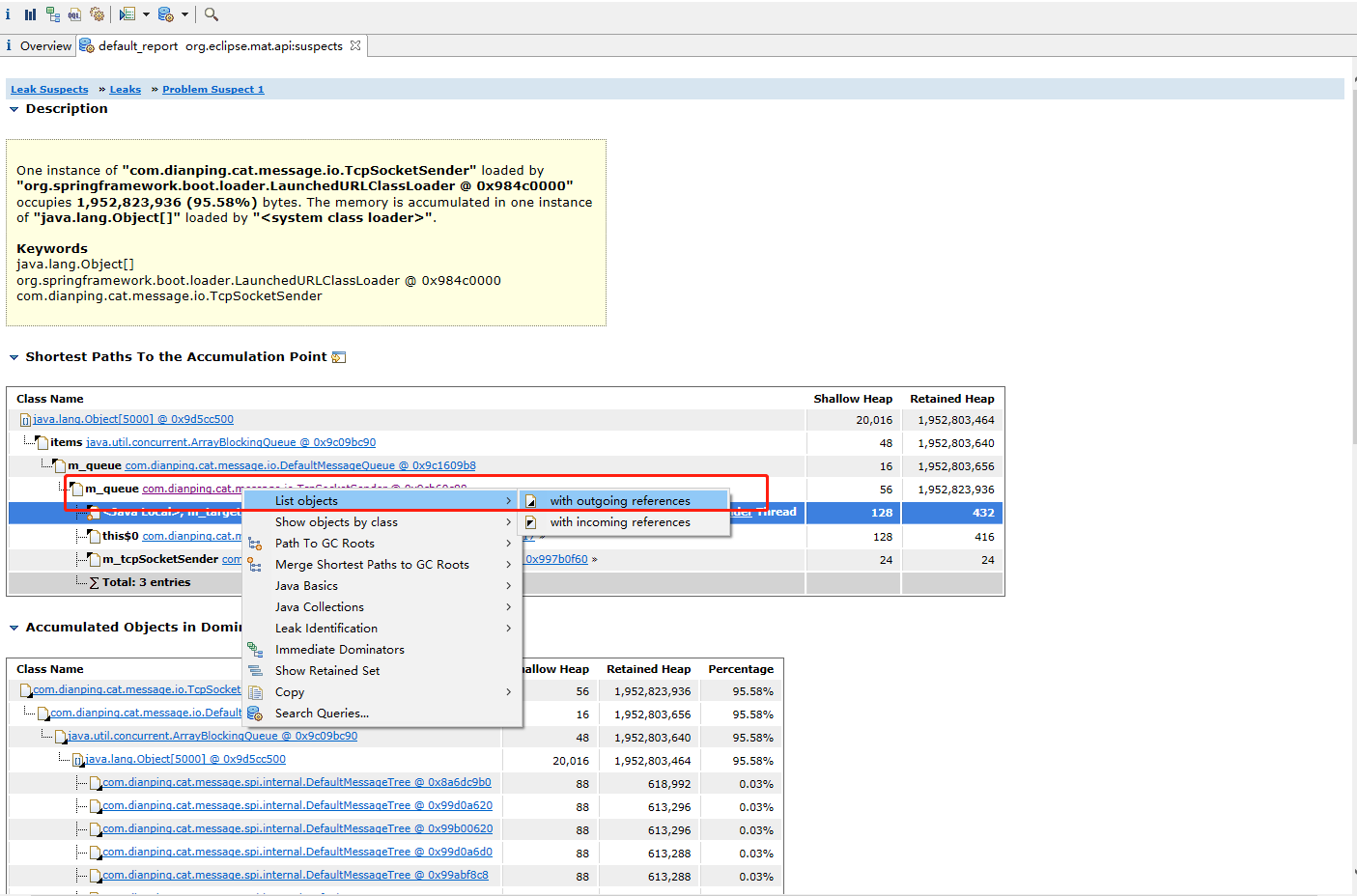
查看TcpSocketSender对象的所的引用信息如下:
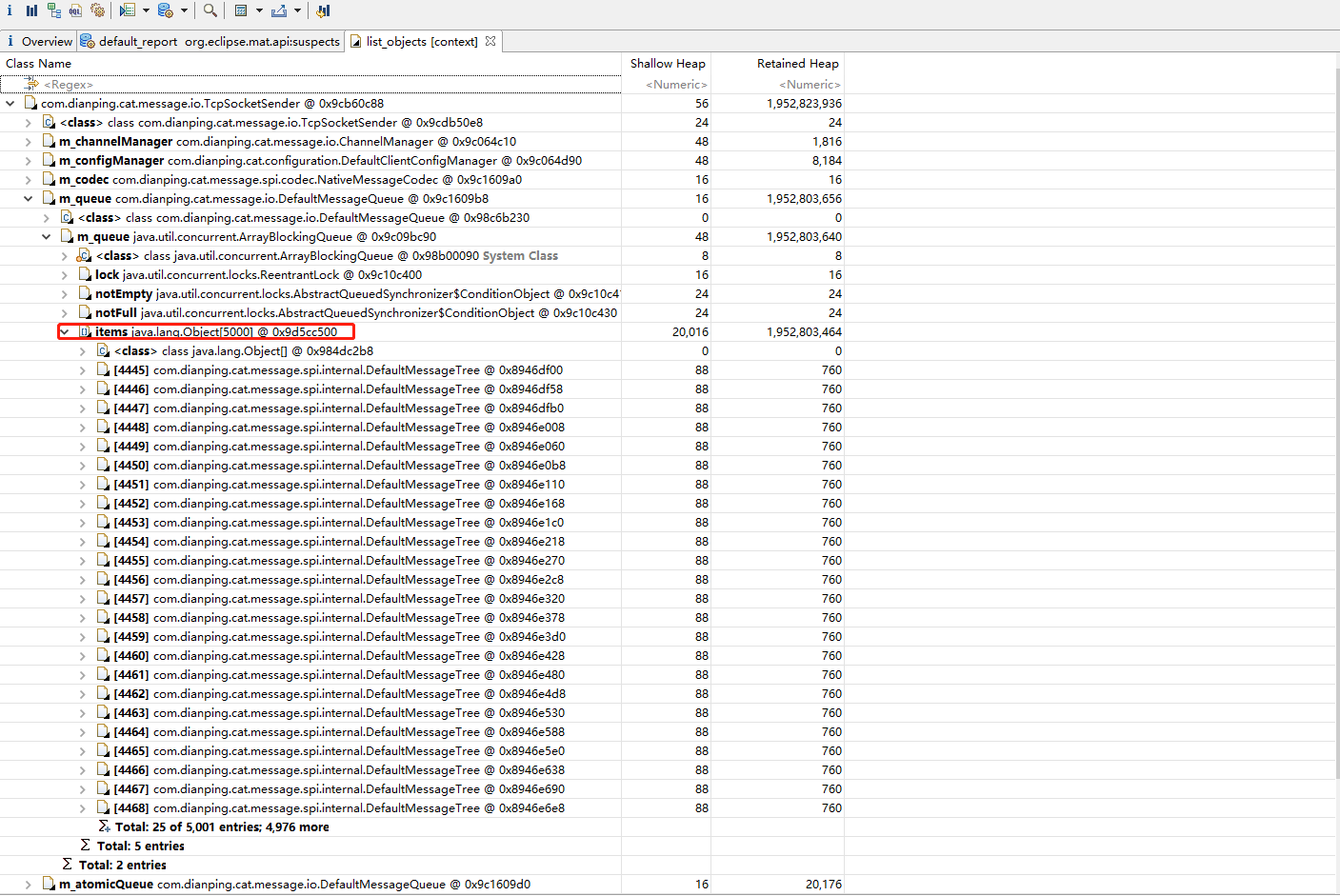
TcpSocketSender内部的DefaultMessageQueue对象持有了一个BlockingQueue,用来保存DefaultMessageTree对象,长度达到了5000,但Retained Heap大小仅760字节,按照计算总共才占用几M内存,但是点击查看更多就会发现有很多0.6M左右的对象,占用了大量内存空间,进一步查看m_data内容可以发现存储的都是采集的日志信息:
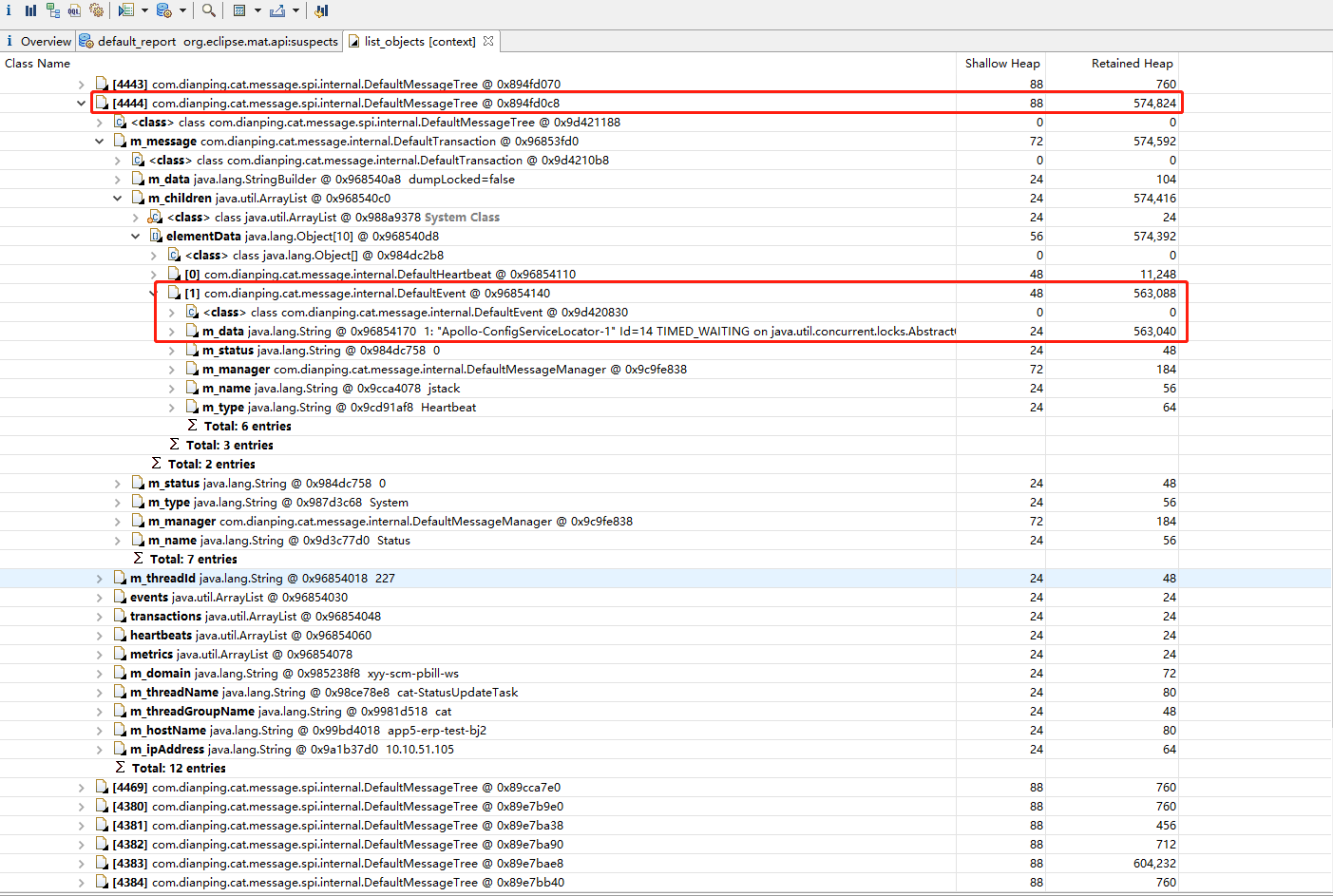
到此为止,我们可以得出结论:CAT客户端与服务端建立连接失败,CAT客户端保存的监控数据发送不出去,随着时间的推移,保存的数据越来越多,却又不能被回收掉,也就是发生了内存泄漏,垃圾收集器不断的进行收集,导致系统CPU飙升到将近100%,最终导致服务不可用。后面发现,由于我们的服务启动的时候设置了“-XX:+HeapDumpOnOutOfMemoryError”和“-XX:HeapDumpPath”启动参数,也在对应的路径下找到了JVM自动生成的dump文件,同时在日志中发现系统最早不可用时候抛出OOM的异常:
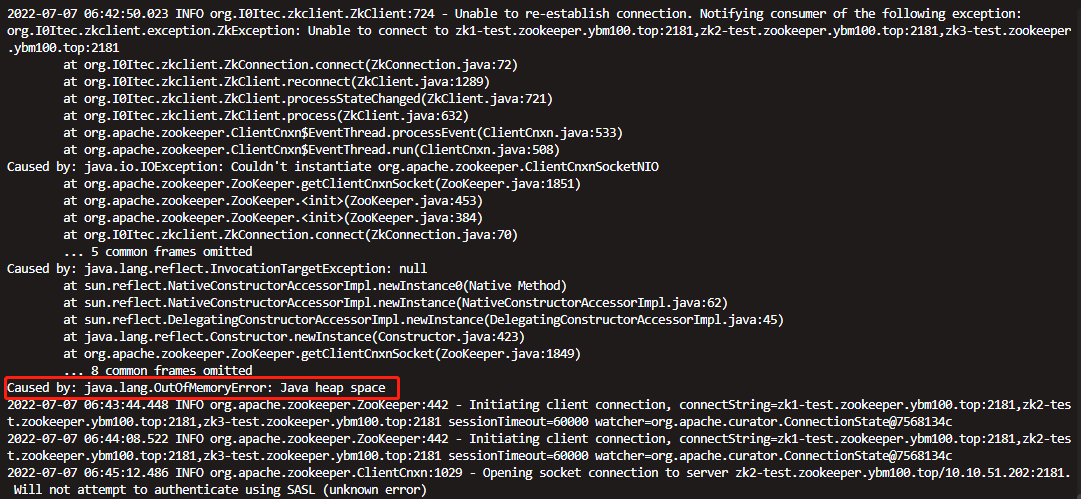
但是问题是,为什么CAT客户端与服务端建立连接会失败?通过咨询运维得知测试环境的CAT服务端已经停掉了,原因是公司要弃用CAT,切换使用全链路工具skywalking,此事我们都知道,我们也按照架构组的要求去掉了系统中的CAT客户端相关jar依赖,但是为何还会有CAT客户端的代码在运行,难道是依赖没有去掉吗?于是通过执行maven命令“mvn dependency:tree”查看项目依赖情况,然后在执行结果中搜索“cat”关键字,果然发现有个其他业务的jar依赖了cat-client:
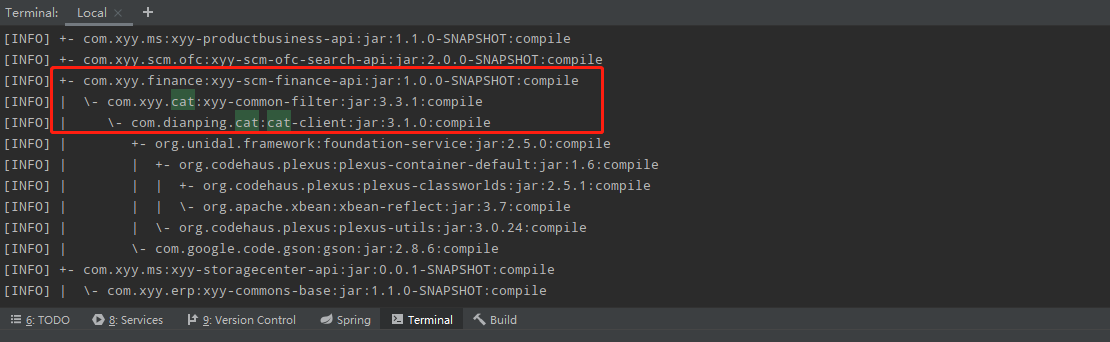
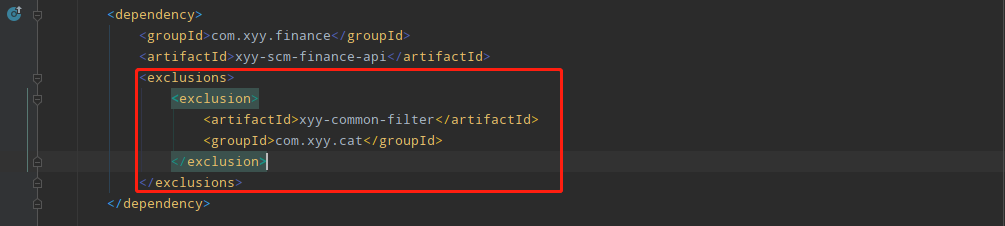
xyy-common-filter是早期公司架构组对cat客户端做的封装,业务项目接入CAT监控需要依赖该jar包,前段时间公司决定切换到skywalking做全链路监控,所以就让各个业务组去掉xyy-common-filter的依赖,我们项目中的依赖已经去掉,却没想到还有其他业务的jar有间接依赖,由于最近各个业务组都报告已经去掉了cat依赖,于是运维就先将测试环境CAT服务端停掉了,后面线上CAT服务端也会被停掉,幸好在测试环境发现了该问题,并刨根问底的探究原因,如果忽略问题,只是简单重启项目解决,到了线上必然造成线上事故。一般来说,项目api包只会放一些dubbo api和简单的bean对象,依赖应该尽量的简单,这样避免其他业务方引用依赖的时候发生jar包冲突,更不应该把cat的依赖加入,我将这个问题反馈到了相关负责的同学,提醒他尽快修改依赖,目前我这边先排除cat依赖临时解决:
3、复盘总结
(1)、作为技术人员面对问题的时候要有探索精神。如果简单的去解决问题或者忽略问题、回避问题,只会导致隐患,而是需要有刨根问底的精神,能不断层层深入,探究问题本质,这样才能从根儿上找到问题的所在,才能根本上解决问题。
(2)、掌握一些原理性的知识和常见的工具是很有必要的。原理性的知识看似平时开发的时候没用,但是在排查疑难问题和理解技术本质、调优的时候是很有用的,同时掌握常见的工具有助于定位线上问题、排查线上问题,否则面对问题只能抓瞎。
(3)、开发人员需要遵守开发规范。公司制定的各项开发规范,大到项目部署流程,小到方法、字段的命名,都是长期经验的总结,能在最大程度上避免隐患,作为开发人员的我们应该遵守这些开发规范。